Appearance
Обучение с подкреплением. ДЗ
Цель задания:
Познакомиться с основами обучения с подкреплением (Reinforcement Learning, RL), понять основные концепции и применить их на практике, используя простой алгоритм Q-Learning для решения задачи.
Задание:
Теоретическая часть:
- Прочитайте материалы о концепциях обучения с подкреплением: агент, среда, действия, награды, состояния, политика, функция ценности и функция награды.
- Напишите краткое эссе (1-2 страницы) о том, как обучение с подкреплением отличается от других видов обучения (например, обучение с учителем и обучение без учителя).
Практическая часть:
- Реализуйте алгоритм Q-Learning для решения задачи "Замкнутый лабиринт" (Gridworld).
- Визуализируйте политику и функцию ценности, найденные вашим агентом.
Дополнительные задания (для продвинутых студентов):
- Реализуйте алгоритм SARSA и сравните его результаты с Q-Learning на той же задаче.
- Изучите и реализуйте epsilon-greedy стратегию для выбора действий.
Все результаты выполнения работы поместите в один блокнот Colab, сохраните, расшарьте для просмотра и направьте преподавателю на проверку.
Подробное описание заданий 2 и 3:
Практическая часть:
Часть 1: Реализация Q-Learning
- Создайте среду "Gridworld" размером 5x5. Ваша задача — найти путь от стартовой клетки (в левом верхнем углу) до целевой клетки (в правом нижнем углу), избегая препятствий.
- Используйте следующую формулу обновления Q-значений:
$ Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)] $
где:
$ s $ — текущее состояние,
$ a $ — текущее действие,
$ r $ — награда,
$ s' $ — новое состояние,
$ \alpha $ — скорость обучения (learning rate),
4 \gamma $ — коэффициент дисконтирования (discount factor).
Пример кода для начала:
pythonimport numpy as np # Параметры alpha = 0.1 gamma = 0.9 epsilon = 0.1 episodes = 1000 grid_size = 5 # Инициализация Q-таблицы Q = np.zeros((grid_size, grid_size, 4)) # Функции для выбора действий и обновления Q-таблицы def choose_action(state): if np.random.rand() < epsilon: return np.random.randint(4) else: return np.argmax(Q[state]) def update_q(state, action, reward, next_state): best_next_action = np.argmax(Q[next_state]) td_target = reward + gamma * Q[next_state][best_next_action] td_error = td_target - Q[state][action] Q[state][action] += alpha * td_error # Обучение агента for episode in range(episodes): state = (0, 0) done = False while not done: action = choose_action(state) next_state, reward, done = step(state, action) update_q(state, action, reward, next_state) state = next_state # Визуализация политики policy = np.argmax(Q, axis=2) print("Оптимальная политика:") print(policy)Часть 2: Визуализация политики и функции ценности
- Визуализируйте оптимальную политику и функцию ценности после обучения.
- Объясните результаты и проанализируйте, как агент принимает решения в разных состояниях.
- Дополнительные задания:
- Реализуйте алгоритм SARSA и сравните его с Q-Learning.
- Внедрите epsilon-greedy стратегию для выбора действий и проанализируйте ее влияние на обучение.
Критерии оценки:
- Понимание теоретических концепций обучения с подкреплением.
- Корректность реализации алгоритма Q-Learning.
- Качество визуализации и анализ результатов.
- Выполнение дополнительных заданий (если применимо).
Примеры кода
Политика: Оптимальная политика показывает действия, которые агент предпочитает в каждом состоянии, чтобы максимизировать награду.
Функция ценности: Функция ценности показывает ожидаемую накопленную награду для каждого состояния.
Реализация Q-Learning
python
import numpy as np
# Параметры
alpha = 0.1
gamma = 0.9
epsilon = 0.1
episodes = 1000
grid_size = 5
# Действия: вверх, вниз, влево, вправо
actions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
# Инициализация Q-таблицы
Q = np.zeros((grid_size, grid_size, len(actions)))
# Функции для выбора действий и обновления Q-таблицы
def choose_action(state):
if np.random.rand() < epsilon:
return np.random.randint(len(actions))
else:
return np.argmax(Q[state])
def step(state, action):
next_state = (state[0] + actions[action][0], state[1] + actions[action][1])
if next_state[0] < 0 or next_state[0] >= grid_size or next_state[1] < 0 or next_state[1] >= grid_size:
next_state = state # оставаться на месте, если выходит за пределы
reward = 1 if next_state == (grid_size-1, grid_size-1) else -0.1
done = next_state == (grid_size-1, grid_size-1)
return next_state, reward, done
def update_q(state, action, reward, next_state):
best_next_action = np.argmax(Q[next_state])
td_target = reward + gamma * Q[next_state][best_next_action]
td_error = td_target - Q[state][action]
Q[state][action] += alpha * td_error
# Обучение агента
for episode in range(episodes):
state = (0, 0)
done = False
while not done:
action = choose_action(state)
next_state, reward, done = step(state, action)
update_q(state, action, reward, next_state)
state = next_state
# Визуализация политики
policy = np.argmax(Q, axis=2)
print("Оптимальная политика:")
print(policy)Оптимальная политика:
[[3 3 1 1 1]
[3 3 1 1 1]
[3 3 3 3 1]
[1 3 3 3 1]
[0 3 3 3 0]]Визуализация политики и функции ценности
python
import matplotlib.pyplot as plt
# Функция ценности
value_function = np.max(Q, axis=2)
plt.figure(figsize=(10, 6))
# Политика
plt.subplot(1, 2, 1)
plt.title('Политика')
plt.imshow(policy, cmap='viridis', origin='upper')
for i in range(grid_size):
for j in range(grid_size):
plt.text(j, i, policy[i, j], ha='center', va='center', color='white')
# Функция ценности
plt.subplot(1, 2, 2)
plt.title('Функция ценности')
plt.imshow(value_function, cmap='viridis', origin='upper')
for i in range(grid_size):
for j in range(grid_size):
plt.text(j, i, round(value_function[i, j], 2), ha='center', va='center', color='white')
plt.show()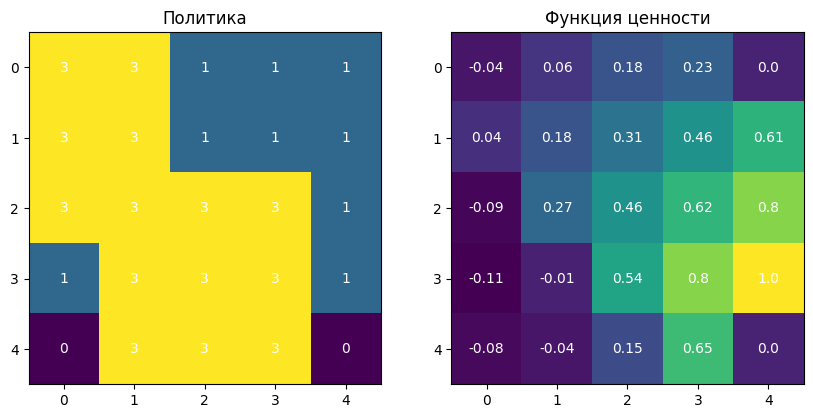
Реализация SARSA
python
def update_sarsa_q(state, action, reward, next_state, next_action):
td_target = reward + gamma * Q[next_state][next_action]
td_error = td_target - Q[state][action]
Q[state][action] += alpha * td_error
# Обучение агента с использованием SARSA
Q = np.zeros((grid_size, grid_size, len(actions)))
for episode in range(episodes):
state = (0, 0)
action = choose_action(state)
done = False
while not done:
next_state, reward, done = step(state, action)
next_action = choose_action(next_state)
update_sarsa_q(state, action, reward, next_state, next_action)
state, action = next_state, next_action
policy_sarsa = np.argmax(Q, axis=2)
print("Оптимальная политика (SARSA):")
print(policy_sarsa) Оптимальная политика (SARSA):
[[3 1 1 1 1]
[3 3 1 3 1]
[1 3 1 1 1]
[3 3 1 3 1]
[3 3 3 3 0]]Реализация epsilon-greedy стратегии
python
def update_sarsa_q(state, action, reward, next_state, next_action):
td_target = reward + gamma * Q[next_state][next_action]
td_error = td_target - Q[state][action]
Q[state][action] += alpha * td_error
# Обучение агента с использованием SARSA
Q = np.zeros((grid_size, grid_size, len(actions)))
for episode in range(episodes):
state = (0, 0)
action = choose_action(state)
done = False
while not done:
next_state, reward, done = step(state, action)
next_action = choose_action(next_state)
update_sarsa_q(state, action, reward, next_state, next_action)
state, action = next_state, next_action
policy_sarsa = np.argmax(Q, axis=2)
print("Оптимальная политика (SARSA):")
print(policy_sarsa) Оптимальная политика (SARSA):
[[3 1 1 1 1]
[3 3 1 1 1]
[3 1 1 1 1]
[3 3 3 1 1]
[3 3 3 3 0]]