Appearance
Обучение с подкреплением
Обучение с подкреплением (Reinforcement Learning, RL) — это метод машинного обучения, в котором агент учится взаимодействовать с окружающей средой, чтобы максимизировать кумулятивную награду. Этот подход основан на пробах и ошибках, и агент сам открывает, какие действия приводят к лучшим результатам.
Подходы к машинному обучению
Обучение с учителем (supervised learning):
- Существует исчерпывающий набор данных (датасет), который задает распределение признакового описания объектов в решаемой задаче.
- Для всех объектов в датасете известно соответствующее значение целевой переменной (может быть меткой номера класса, вещественным числом и тому подобным).
- Нужно (возможно) подобрать некоторую гипотетическую функцию, которая ставит в соответствие признаковому описанию некоторого объекта число — целевую переменную.
- Можно построить дифференцируемую функцию (так называемую функцию потерь, loss), которая характеризует качество подобранной функции как аппроксиматора искомой зависимости между признаками и целевой переменной.
Типичный пример — решение задачи классификации рукописных цифр в датасете MNIST при помощи CNN.
Обучение без учителя (unsupervised learning):
- Существует исчерпывающий набор данных (датасет), который эмпирически задает распределение признакового описания объектов в решаемой задаче.
- Для объектов в датасете неизвестно соответствующее значение целевой переменной.
- Нужно преобразовать имеющиеся признаковые описания объектов в новое представление, в котором будут видны закономерности и скрытые связи между ними.
Типичный пример — использование метода k-средних для решения задачи кластеризации.
Ключевой особенностью этих ML-парадигм является работа с датасетом как с исчерпывающей и не изменяющейся сущностью. По сути, именно набор данных и определяет решаемую в этих подходах задачу.

Однако, существуют задачи, в которых невозможно составить такой исчерпывающий датасет.
Например, разрабатывая автопилот для автомобиля, мы вряд ли сможем составить обучающую выборку, в которой будут перечислены все возможные дорожные ситуации в условиях плотного городского трафика, для которых к тому же будет известна разметка "ground true" целевой переменной о предпочтительном решении автопилота в них.
Невозможность собрать исчерпывающий датасет во многом может быть связана с тем, как в примере с автопилотом автомобиля, что результат работы алгоритма может существенно изменить состояние окружающей его среды, которая и является источником данных.
Не имея всей картины возможных действий и их последствий, мы можем предоставить нашему алгоритму возможность взаимодействовать с источником данных (средой) и постфактум оценить действия нашего алгоритма (агента), и, используя эту оценку, подстроить алгоритм так, чтобы он чаще совершал желательные действия, и реже — нежелательные.
Основные концепции обучения с подкреплением
- Агент: Субъект, принимающий решения.
- Среда (Environment): Всё, с чем взаимодействует агент.
- Действие (Action): Выбор агента в каждый момент времени.
- Состояние (State): Текущее состояние среды, которое наблюдает агент.
- Награда (Reward): Обратная связь от среды, сигнализирующая о качестве действия агента.
- Политика (Policy): Стратегия агента по выбору действий в различных состояниях.
- Функция ценности (Value Function): Оценка "полезности" состояний или действий.
Пример процесса RL
- Агент наблюдает текущее состояние среды.
- Агент выбирает действие на основе своей политики.
- Среда изменяет своё состояние в ответ на действие агента.
- Агент получает награду от среды.
- Агент обновляет свою политику, основываясь на полученной награде и новом состоянии.
Методы обучения с подкреплением
Методы на основе ценности (Value-based methods):
- Q-Learning: Агент учится оценивать качество каждого действия в каждом состоянии (функция Q).
- SARSA (State-Action-Reward-State-Action): Похож на Q-Learning, но обновляет значения на основе действий, реально выполненных агентом.
Методы на основе политики (Policy-based methods):
- REINFORCE: Агент непосредственно учится политике, которая максимизирует ожидаемую награду.
- Actor-Critic: Сочетает методы на основе ценности и политики; агент имеет два компонента: актер (actor), который выбирает действия, и критик (critic), который оценивает эти действия.
Методы обучения с использованием моделей (Model-based methods):
- Включают создание модели среды и использование этой модели для планирования и принятия решений.
Пример использования Q-Learning
Пример обучения агента с использованием Q-Learning в среде Gridworld:
python
!pip install gymnasium
Code cell <Td5AS285rd2V>
# %% [code]
import numpy as np
import random
from collections import defaultdict
# Параметры среды
GRID_SIZE = 5
NUM_EPISODES = 500
MAX_STEPS_PER_EPISODE = 100
# Параметры Q-Learning
LEARNING_RATE = 0.1 # Скорость обучения alpha
DISCOUNT_FACTOR = 0.99 # Дисконтирующий фактор gamma
EPSILON = 1.0 # Вероятность выбора случайного действия (всегда случайное действие)
# Определение наград и действий
REWARDS = np.zeros((GRID_SIZE, GRID_SIZE))
REWARDS[4, 4] = 1 # Целевая клетка с наградой
ACTIONS = ["UP", "DOWN", "LEFT", "RIGHT"]
# Функция для выбора следующего действия на основе epsilon-greedy политики
def epsilon_greedy_action(Q, state, epsilon):
if random.uniform(0, 1) < epsilon:
return random.choice(ACTIONS)
else:
return max(ACTIONS, key=lambda action: Q[state][action])
# Функция для выполнения действия и получения нового состояния и награды
def step(state, action):
row, col = state
if action == "UP" and row > 0:
row -= 1
elif action == "DOWN" and row < GRID_SIZE - 1:
row += 1
elif action == "LEFT" and col > 0:
col -= 1
elif action == "RIGHT" and col < GRID_SIZE - 1:
col += 1
new_state = (row, col)
reward = REWARDS[row, col]
return new_state, reward
# Инициализация Q-таблицы
Q = defaultdict(lambda: {action: 0 for action in ACTIONS})
# Обучение агента с использованием Q-Learning
for episode in range(NUM_EPISODES):
state = (0, 0)
for step_num in range(MAX_STEPS_PER_EPISODE):
action = epsilon_greedy_action(Q, state, EPSILON)
new_state, reward = step(state, action)
# Обновление Q-значений
best_next_action = max(ACTIONS, key=lambda action: Q[new_state][action])
td_target = reward + DISCOUNT_FACTOR * Q[new_state][best_next_action]
td_error = td_target - Q[state][action]
Q[state][action] += LEARNING_RATE * td_error
state = new_state
# Вывод Q-таблицы (для отладки или анализа)
for state in Q:
print(f"State {state}: {Q[state]}")Как трактовать эти результаты?
Допустим, ваши результаты выглядят так (результаты могут отличаться от эксперимента к эксперименту):

Эти строки представляют собой содержимое Q-таблицы, где каждая строка описывает значение Q-функции для состояния и всех возможных действий в этом состоянии. Давайте разберем пример:
State (0, 1) - это состояние
(0, 1), представляющее клетку на сетке в первой строке и второй колонне.{'UP': 29.90826580661368, 'DOWN': 30.48636189701739, 'LEFT': 29.3916963928853, 'RIGHT': 30.337091666751274} - это словарь, содержащий оценки Q-функции для всех возможных действий из этого состояния:
- 'UP': 29.91 - оценка действия "вверх".
- 'DOWN': 30.49 - оценка действия "вниз".
- 'LEFT': 29.39 - оценка действия "влево".
- 'RIGHT': 30.34 - оценка действия "вправо".
Как интерпретировать эти данные:
- Q-значения отражают ценность (ожидаемую награду) для выполнения действия в данном состоянии, следуя политике, которую агент изучает.
- Например, в состоянии
(0, 1):- Действие "вверх" имеет оценку 29.91.
- Действие "вниз" имеет оценку 30.49.
- Действие "влево" имеет оценку 29.39.
- Действие "вправо" имеет оценку 30.34.
Как используется Q-таблица:
Обучение: Агент обучается, обновляя Q-значения для различных состояний и действий на основе вознаграждения и ожидаемых Q-значений для следующих состояний.
Выбор действия:
- Агент использует стратегию epsilon-greedy, чтобы выбирать действия: с вероятностью
1 - epsilonвыбирается действие с максимальным Q-значением, а с вероятностьюepsilonвыбирается случайное действие.
- Агент использует стратегию epsilon-greedy, чтобы выбирать действия: с вероятностью
Политика: В конце обучения агент выбирает действие с максимальным Q-значением в каждом состоянии, что определяет оптимальную стратегию поведения.
Визуализация:
Этот код создаст график с Q-значениями для всех состояний и действий, отражая оптимальную стратегию агента после завершения обучения.
python
import numpy as np
import random
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def visualize_policy(Q):
fig, ax = plt.subplots()
ax.set_xticks(np.arange(0, GRID_SIZE, 1))
ax.set_yticks(np.arange(0, GRID_SIZE, 1))
ax.grid()
for state in Q:
row, col = state
if (row, col) == (4, 4):
ax.add_patch(patches.Rectangle((col, row), 1, 1, color='green')) # Целевая клетка
else:
ax.add_patch(patches.Rectangle((col, row), 1, 1, color='white', fill=False)) # Обычная клетка
if len(Q[state]) > 0:
action = max(Q[state], key=Q[state].get)
ax.text(col + 0.5, row + 0.5, action, fontsize=12, ha='center', va='center')
ax.set_xlim(0, GRID_SIZE)
ax.set_ylim(0, GRID_SIZE)
ax.invert_yaxis()
ax.set_aspect('equal')
plt.show()python
# Инициализация Q-таблицы
Q = defaultdict(lambda: {action: 0 for action in ACTIONS})
# Обучение агента с использованием Q-Learning
for episode in range(NUM_EPISODES):
state = (0, 0)
for step_num in range(MAX_STEPS_PER_EPISODE):
action = epsilon_greedy_action(Q, state, EPSILON)
new_state, reward = step(state, action)
# Обновление Q-значений
best_next_action = max(ACTIONS, key=lambda action: Q[new_state][action])
td_target = reward + DISCOUNT_FACTOR * Q[new_state][best_next_action]
td_error = td_target - Q[state][action]
Q[state][action] += LEARNING_RATE * td_error
state = new_state
# Показать последнюю политику
visualize_policy(Q)MountainCar (горный автомобиль) - это классическая задача в области обучения с подкреплением, которая часто используется для тестирования и сравнения алгоритмов обучения, таких как Q-обучение и его модификации.
Описание задачи:
MountainCar моделирует ситуацию, в которой автомобиль должен достичь вершины горы через долину, где гравитация работает против движения автомобиля. Основные характеристики задачи:
Состояние (State): Состояние автомобиля описывается двумя переменными:
- Позиция автомобиля $ \text{position} $ на оси X.
- Скорость $ \text{velocity} $ автомобиля.
В задаче MountainCar нет фиксированных состояний; это непрерывное пространство состояний.
Действия (Actions): Водитель автомобиля может предпринять одно из трех действий:
- Ускорение влево.
- Не менять скорость.
- Ускорение вправо.
Эти действия представляют собой дискретные выборы для модели.
Награды (Rewards): Награда равна 0 на всех временных шагах, кроме случаев, когда автомобиль достигает вершины холма. В этом случае награда равна 1. Цель состоит в том, чтобы автомобиль достиг вершины как можно быстрее.
Цель (Goal): Достигнуть вершины холма, где позиция $ \text{position} $ больше или равна заданной целевой позиции.
Цель обучения:
Основная цель обучения в задаче MountainCar - научить автомобиль использовать управление (действия) и состояния (позиция и скорость) для достижения вершины холма, минимизируя количество шагов или время, потраченное на это.
Алгоритмы обучения:
Для решения задачи MountainCar можно использовать различные методы обучения с подкреплением, такие как:
Q-обучение (Q-Learning): Алгоритм, который обновляет оценки Q-функции для пары (состояние, действие) в процессе обучения. Эти оценки используются для выбора оптимальных действий в каждом состоянии.
Deep Q-Networks (DQN): Вариант Q-обучения, который использует нейронные сети для оценки Q-функции, что позволяет более эффективно обрабатывать сложные пространства состояний.
Policy Gradient Methods: Методы, которые напрямую оптимизируют стратегию (политику) агента без явного вычисления Q-функции.
Рассмотрим код илюстрирующий решение задачи:
Создание среды: Используется библиотека OpenAI Gym для создания среды
MountainCar-v0.Симуляция и запись кадров: В цикле производится выполнение симуляции, где каждый шаг (action) задается фиксированным значением (
action = 2), что соответствует движению автомобиля вправо. Каждый кадр среды рендерится в режимеrgb_arrayи сохраняется в массивframes.Анимация: После завершения симуляции создается анимация с помощью библиотеки
matplotlib.animation.FuncAnimation. Функцияinitинициализирует ось для отображения первого кадра, а функцияanimateотображает каждый последующий кадр.Отображение анимации в Jupyter Notebook: Используется
display(HTML(anim.to_jshtml())), чтобы отобразить анимацию непосредственно в ячейке Jupyter Notebook.Опционально сохранение анимации: Раскомментированная строка
anim.save('mountain_car.gif', writer='pillow', fps=30)позволяет сохранить анимацию как файл GIF с использованием библиотекиPillowи частотой кадров 30 кадров в секунду.
Таким образом, данный код выполняет симуляцию в среде MountainCar-v0, записывает каждый кадр симуляции, создает анимацию и отображает её в Jupyter Notebook, что позволяет визуально отследить поведение и результаты работы алгоритма в этой среде.
python
import gym
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from IPython.display import display, HTML
# Создаем среду
env = gym.make("MountainCar-v0")
obs = env.reset()
# Массив для хранения кадров
frames = []
# Выполняем симуляцию и сохраняем кадры
for _ in range(1000): # Ограничиваем количество шагов
# Если скорость отрицательная, двигаемся влево, иначе вправо
action = 0 if obs[1] < 0 else 2
obs, reward, done, info = env.step(action)
# Рендерим кадр и сохраняем его
frame = env.render(mode='rgb_array')
frames.append(frame)
if done:
break
env.close()
print(f"Симуляция завершена. Всего кадров: {len(frames)}")
# Создаем фигуру и ось
fig, ax = plt.subplots(figsize=(8, 6))
# Функция инициализации для анимации
def init():
ax.clear()
return ax.imshow(frames[0]),
# Функция анимации
def animate(i):
ax.clear()
return ax.imshow(frames[i]),
# Создаем анимацию
anim = FuncAnimation(fig, animate, init_func=init, frames=len(frames),
interval=20, blit=True)
# Отображаем анимацию в Jupyter notebook
display(HTML(anim.to_jshtml()))
# Если вы хотите сохранить анимацию как gif, раскомментируйте следующую строку:
anim.save('mountain_car.gif', writer='pillow', fps=30)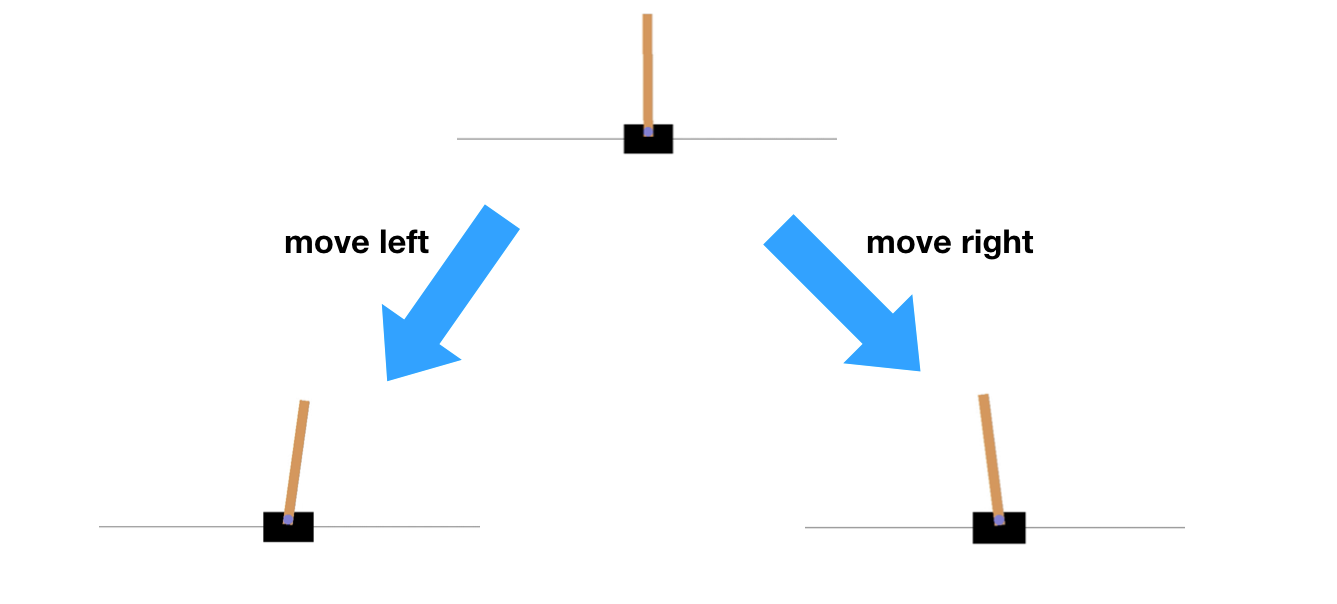
Задача: CartPole (Балансирующий шест)
CartPole - это классическая задача в области обучения с подкреплением. Суть задачи заключается в следующем:
- Есть тележка, которая может двигаться влево и вправо по одномерной траектории.
- На тележке установлен шест (pole), который может свободно вращаться в вертикальной плоскости.
- Цель - удержать шест в вертикальном положении как можно дольше, двигая тележку влево или вправо.
Состояние среды описывается четырьмя параметрами:
- Позиция тележки
- Скорость тележки
- Угол наклона шеста
- Угловая скорость шеста
Агент может выполнять два действия:
- Двигать тележку влево
- Двигать тележку вправо
Эпизод заканчивается, если:
- Угол наклона шеста становится слишком большим (шест падает)
- Тележка выходит за пределы допустимой области
- Эпизод длится более 500 шагов (в нашей реализации)
Решение задачи:
Для решения этой задачи в коде используется метод глубокого Q-обучения (Deep Q-Learning, DQN). Вот как это работает:
Нейронная сеть (Q-сеть):
- Входной слой: 4 нейрона (по числу параметров состояния)
- Два скрытых слоя по 24 нейрона каждый с активацией ReLU
- Выходной слой: 2 нейрона (по числу возможных действий)
Процесс обучения:
а. Инициализация:
- Создается среда CartPole
- Инициализируется нейронная сеть
- Создается память для хранения опыта (deque)
б. Цикл обучения (для каждого эпизода):
- Сброс среды в начальное состояние
- Цикл взаимодействия со средой:
- Выбор действия (с использованием ε-жадной стратегии)
- Выполнение действия и получение нового состояния, награды и флага завершения
- Сохранение опыта в памяти
- Если память достаточно заполнена, производится обучение на мини-батче
в. Обучение (функция replay):
- Выборка случайного мини-батча из памяти
- Вычисление целевых Q-значений с использованием формулы Беллмана
- Обновление весов нейронной сети для минимизации ошибки между предсказанными и целевыми Q-значениями
Особенности реализации:
- Использование ε-жадной стратегии для баланса между исследованием и использованием
- Постепенное уменьшение ε для перехода от исследования к использованию
- Использование техники Experience Replay для стабилизации обучения
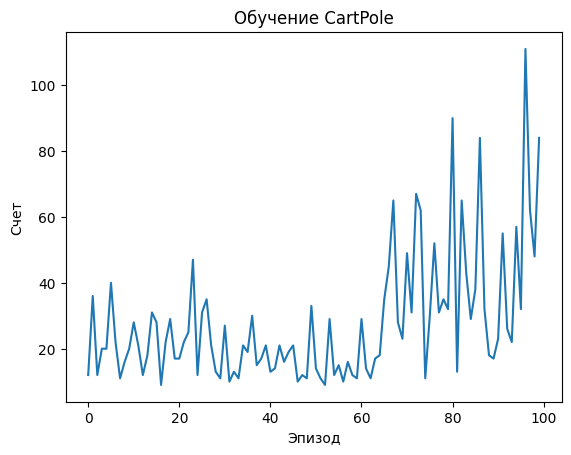
Визуализация результатов:
- После обучения строится график, показывающий, как изменялся счет (длительность эпизода) с течением времени
Этот код демонстрирует, как агент постепенно учится удерживать шест в вертикальном положении, увеличивая длительность эпизодов. Начиная с случайных действий, агент постепенно улучшает свою стратегию, обучаясь на собственном опыте.
python
# !pip install gym
# !pip install matplotlib
import gym
import numpy as np
import matplotlib.pyplot as plt
from collections import deque
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import random
# Создаем среду CartPole
env = gym.make('CartPole-v1')
# Определяем модель нейронной сети
def create_model(state_size, action_size):
model = Sequential([
Dense(24, activation='relu', input_dim=state_size),
Dense(24, activation='relu'),
Dense(action_size, activation='linear')
])
model.compile(loss='mse', optimizer=Adam(learning_rate=0.001))
return model
# Параметры обучения
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
model = create_model(state_size, action_size)
memory = deque(maxlen=2000)
gamma = 0.95
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
batch_size = 32
# Функция для выбора действия
def act(state):
if np.random.rand() <= epsilon:
return env.action_space.sample()
act_values = model.predict(state)
return np.argmax(act_values[0])
# Функция для обучения модели
def replay(batch_size):
minibatch = random.sample(memory, batch_size)
states = np.array([i[0][0] for i in minibatch])
actions = np.array([i[1] for i in minibatch])
rewards = np.array([i[2] for i in minibatch])
next_states = np.array([i[3][0] for i in minibatch])
dones = np.array([i[4] for i in minibatch])
targets = rewards + gamma * np.amax(model.predict(next_states), axis=1) * (1 - dones)
target_f = model.predict(states)
target_f[np.arange(batch_size), actions] = targets
model.fit(states, target_f, epochs=1, verbose=0)
# Обучение
episodes = 100
scores = []
for e in range(episodes):
state = env.reset()
if isinstance(state, tuple):
state = state[0]
state = np.reshape(state, [1, state_size])
score = 0
for time in range(500):
action = act(state)
step_result = env.step(action)
if len(step_result) == 4:
next_state, reward, done, _ = step_result
else:
next_state, reward, terminated, truncated, _ = step_result
done = terminated or truncated
next_state = np.reshape(next_state, [1, state_size])
memory.append((state, action, reward, next_state, done))
state = next_state
score += reward
if done:
break
if len(memory) > batch_size:
replay(batch_size)
scores.append(score)
epsilon = max(epsilon_min, epsilon_decay * epsilon)
print(f"Episode: {e+1}/{episodes}, Score: {score}, Epsilon: {epsilon:.2f}")
# Визуализация результатов
plt.plot(scores)
plt.title('Обучение CartPole')
plt.xlabel('Эпизод')
plt.ylabel('Счет')
plt.show()Episode: 1/100, Score: 35.0, Epsilon: 0.87
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step
Episode: 2/100, Score: 21.0, Epsilon: 0.87
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step
...
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step
Episode: 98/100, Score: 62.0, Epsilon: 0.61
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step
Episode: 99/100, Score: 48.0, Epsilon: 0.61
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 38ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step
Episode: 100/100, Score: 84.0, Epsilon: 0.61