Appearance
Neural Networks - Нейронные сети
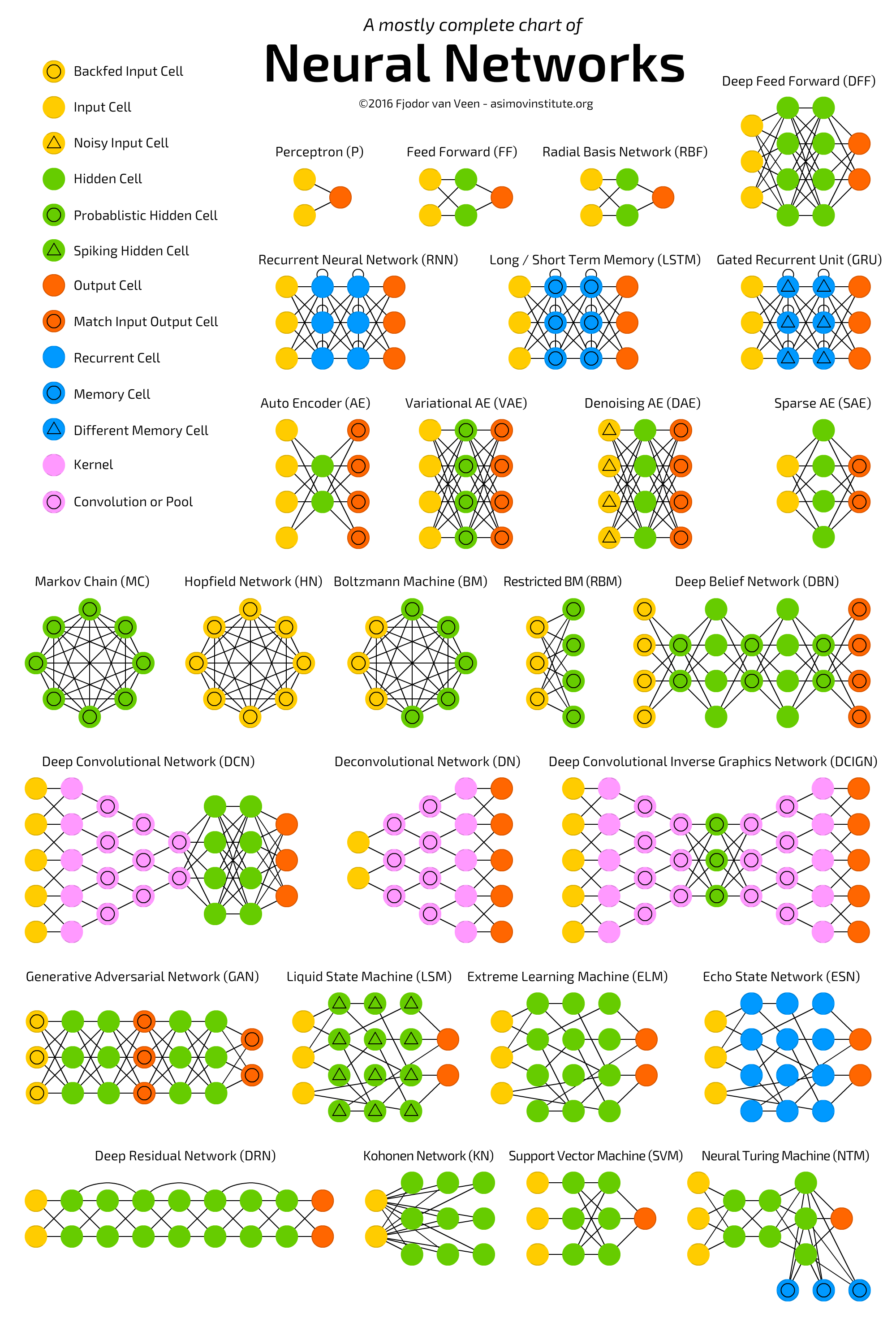
Коротко о каждом типе ячеек и операций:
Ячейка обратной связи входа (Backfed Input Cell):
- Принимает входные данные и обратную связь от других частей сети
- Позволяет сети корректировать входы на основе предыдущих результатов
- Часто используется в генеративных и рекуррентных моделях
Входная ячейка (Input Cell):
- Первый слой нейронной сети
- Принимает исходные данные для обработки
- Передает информацию в следующие слои без изменений
Шумная входная ячейка (Noisy Input Cell):
- Добавляет случайный шум к входным данным
- Улучшает обобщающую способность сети
- Помогает предотвратить переобучение
Скрытая ячейка (Hidden Cell):
- Находится между входным и выходным слоями
- Обрабатывает и трансформирует данные
- Извлекает и комбинирует признаки
Вероятностная скрытая ячейка (Probabilistic Hidden Cell):
- Использует вероятностные методы в обработке данных
- Может моделировать неопределенность
- Часто применяется в байесовских нейронных сетях
Импульсная скрытая ячейка (Spiking Hidden Cell):
- Имитирует работу биологических нейронов
- Активируется импульсно, а не непрерывно
- Эффективна для обработки временных последовательностей
Выходная ячейка (Output Cell):
- Последний слой нейронной сети
- Предоставляет конечный результат обработки
- Форма выхода зависит от решаемой задачи
Ячейка соответствия входа-выхода (Match Input Output Cell):
- Сравнивает входные и выходные данные
- Используется для обучения с учителем
- Помогает оценить точность модели
Рекуррентная ячейка (Recurrent Cell):
- Имеет обратные связи
- Сохраняет информацию о предыдущих состояниях
- Эффективна для обработки последовательностей
Ячейка памяти (Memory Cell):
- Хранит информацию в течение длительного времени
- Ключевой компонент LSTM сетей
- Помогает решать проблему исчезающего градиента
Другая ячейка памяти (Different Memory Cell):
- Альтернативная реализация памяти в нейронных сетях
- Может иметь специфические механизмы хранения и извлечения информации
Ядро (Kernel):
- Матрица весов для свёрточной операции
- Определяет, как извлекаются признаки из входных данных
- Ключевой элемент в свёрточных нейронных сетях
Свёртка или пулинг (Convolution or Pool):
- Свёртка: операция для извлечения признаков
- Пулинг: уменьшение размерности данных
- Основные операции в свёрточных нейронных сетях
Каждый из этих элементов играет важную роль в различных архитектурах нейронных сетей, позволяя им эффективно решать широкий спектр задач машинного обучения.
Классификация различных архитектур нейронных сетей осуществляеися в зависимости от их структуры и предназначения.
Основные типы нейросетей:
- Прямые нейронные сети (Feedforward Neural Networks, FNN) • Это самые простые нейронные сети, где информация передается только в одном направлении: от входного слоя через скрытые слои к выходному слою. • Примеры: многослойный персептрон (MLP).
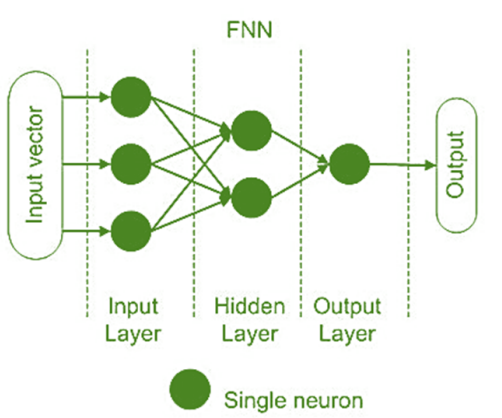
Нейронные сети прямого распространения — это самый простой и базовый тип нейронных сетей. Они состоят из серии слоев, каждый из которых содержит набор нейронов, которые выполняют некоторые математические операции над входными данными.
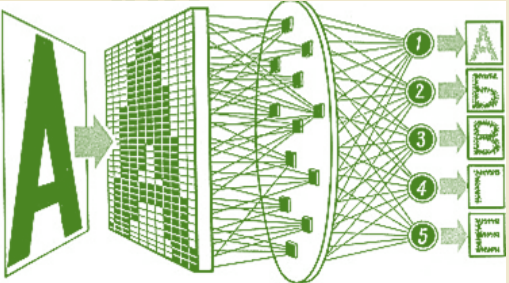
Данные передаются в одном направлении, от входного слоя к выходному, без каких-либо петель обратной связи или памяти. Нейронные сети с прямой связью хороши в изучении статических шаблонов и сопоставлении фиксированных входных данных с выходными. Например, распознание изображений. Однако они не могут обрабатывать последовательные данные, такие как текст, речь или видео...
Одно из первых крупных коммерческих применений FNN - предсказание стиля вождения (он меняется от опыта, возраста, семейного положения и социального статуса водителя).
24% - рост доходности портфеля перестрахования.
- Свёрточные нейронные сети (Convolutional Neural Networks, CNN)
- Используются в основном для обработки изображений и видеоматериалов.
- Состоят из свёрточных слоев, объединительных слоев и полносвязных слоев.
- Примеры: AlexNet, VGG, ResNet.

Сверточные нейронные сети — это тип нейронных сетей, которые разрабатывались для обработки изображений, распознания образов. В основе технология "свертки" входящих матриц на основе фильтрации Сверточный слой является основой CNN, и именно здесь происходит большая часть вычислений.
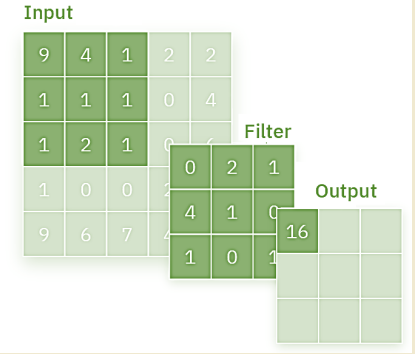
Предположим, что на входе будет цветное изображение, состоящее из матрицы пикселей. Это означает, что входные данные будут иметь три измерения — RGB. У нас также есть детектор признаков, также известный как ядро или фильтр, который будет проверять элементы изображения, проверяя, присутствует ли признак. Этот процесс называется свертка.

- Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
- Имеют связи, которые образуют направленный цикл, что позволяет учитывать временные зависимости.
- Примеры: LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit).
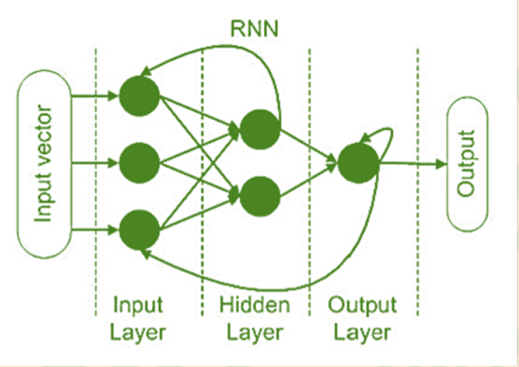
Рекуррентные нейронные сети — это тип нейронных сетей, которые могут работать с последовательными или временными данными. У них есть специальная функция, которая позволяет им хранить некоторую информацию из предыдущих входов и выходов.
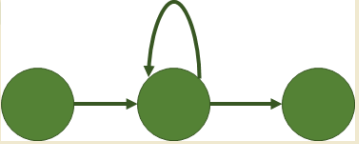
Эта особенность называется рекуррентным соединением, которое представляет собой петлю, соединяющую нейрон с самим собой или с другим нейроном в том же слое. Рекуррентные нейронные сети могут использовать это соединение, чтобы запоминать некоторые аспекты прошлых данных и использовать их для влияния на текущий результат. Рекуррентные нейронные сети хорошо изучают динамические шаблоны и фиксируют долгосрочные зависимости и контекст.
RNN (и их более продвинутые "потомки") стали широко использоваться для прогнозирования спроса на товары, что помогает компаниям управлять запасами более эффективно. RNN - Модель может анализировать исторические данные о продажах, сезонные тренды, праздники и другие факторы для точного прогнозирования объемов будущего спроса.
4. Генеративно-состязательные сети (Generative Adversarial Networks, GAN)
- Состоят из двух сетей: генератора и дискриминатора, которые соревнуются друг с другом.
- Используются для генерации новых данных, таких как изображения, тексты.
- Примеры: DCGAN, StyleGAN.

Generative Adversarial Networks (GANs) – это класс моделей глубокого машинного обучения, изобретенный Иэном Гудфеллоу и его коллегами в 2014 году. GANs состоят из двух нейронных сетей – генератора и дискриминатора, которые соревнуются друг с другом в рамках игры с нулевой суммой. Эти модели стали чрезвычайно популярными благодаря своей способности генерировать данные, которые очень похожи на реальные данные.
Структура и принцип работы GANs
Генератор (G): Это нейронная сеть, задача которой – создавать фейковые данные, которые как можно больше похожи на реальные данные. Генератор берет случайный шум (обычно из нормального распределения) и преобразует его в данные.
Дискриминатор (D): Это нейронная сеть, задача которой – различать реальные данные и данные, созданные генератором. Дискриминатор берет данные и возвращает вероятность того, что они являются реальными.
Процесс обучения
Обучение дискриминатора: Дискриминатор обучается на реальных данных и данных, созданных генератором. Его задача – научиться правильно классифицировать реальные и фейковые данные.
Обучение генератора: Генератор обучается на основании обратной связи от дискриминатора. Его цель – улучшить свои навыки создания фейковых данных, чтобы дискриминатор не мог их отличить от реальных данных.
Процесс обучения проходит в несколько этапов:
- Генератор создает фейковые данные.
- Эти данные вместе с реальными подаются на вход дискриминатору.
- Дискриминатор обучается различать фейковые и реальные данные.
- Генератор обновляет свои параметры, чтобы улучшить свои данные и обмануть дискриминатор.
Алгоритм обучения
- Генератор берет случайный шум $ z $ и генерирует из него данные $ G(z) $.
- Дискриминатор принимает как реальные данные $ x $, так и сгенерированные данные $ G(z) $, и возвращает вероятности $ D(x) $ и $ D(G(z)) $.
- Дискриминатор обновляет свои веса, чтобы увеличить $ D(x) $ и уменьшить $ D(G(z)) $.
- Генератор обновляет свои веса, чтобы увеличить $ D(G(z)) $, то есть стремится обмануть дискриминатор.
Применение GANs
- Генерация изображений: GANs могут создавать реалистичные изображения людей, животных, объектов и даже вымышленных сцен.
- Улучшение качества изображений: GANs используются для увеличения разрешения изображений (суперрезолюция).
- Перенос стиля: GANs могут изменять стиль изображения, например, превращать фотографии в рисунки.
- Создание данных для обучения: GANs могут генерировать данные для обучения моделей, когда реальных данных недостаточно.
- Генерация текстов и музыки: GANs могут использоваться для создания новых текстов и музыкальных композиций.
Сети GAN использовались для выполнения таких задач, как предсказание старения лица, а также для создания «глубоких фейковых» изображений и видеороликов знаменитостей и политиков.
- Автокодировщики (Autoencoders)
- спользуются для обучения эффективных кодировок данных.
- Состоят из кодировщика и декодировщика.
- Примеры: вариационные автокодировщики (VAE), сверточные автокодировщики (CAE).
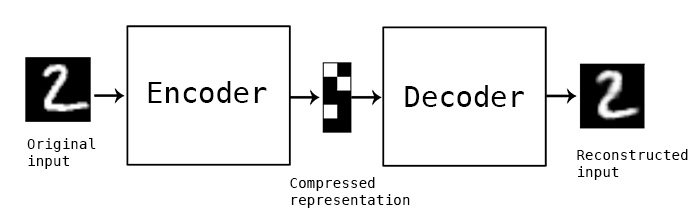
Автокодировщики (autoencoders) — это тип искусственной нейронной сети, используемой для обучения эффективных кодировок данных. Главная идея автокодировщиков состоит в том, чтобы сжать входные данные в скрытое представление и затем попытаться восстановить исходные данные из этого представления. Автокодировщики обычно используются для задач, связанных с уменьшением размерности, обнаружением аномалий, генерацией данных и обучением признаков.
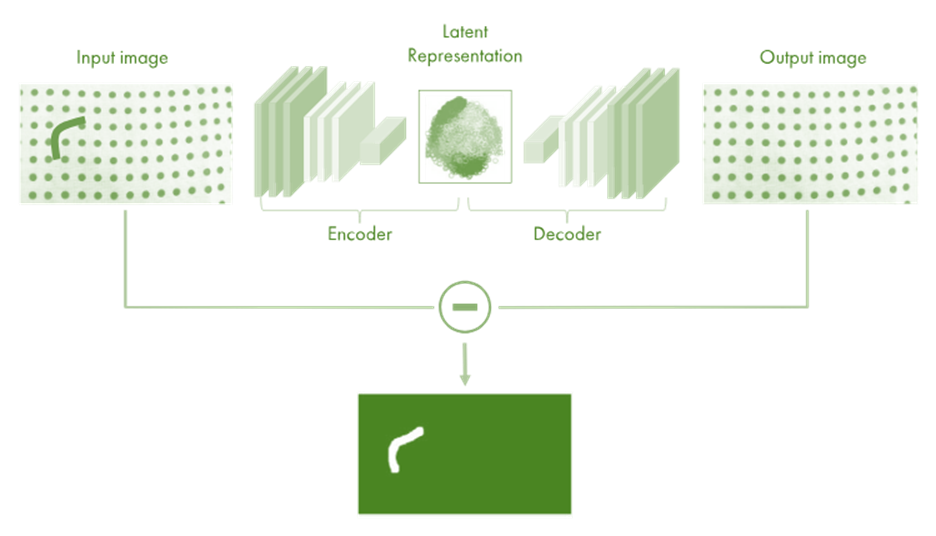
Структура автокодировщика
Автокодировщики состоят из двух основных частей:
Энкодер (кодировщик): Эта часть сети принимает входные данные и преобразует их в сжатое (скрытое) представление. Энкодер обычно состоит из нескольких слоев нейронной сети, которые постепенно уменьшают размерность данных.
Декодер (декодировщик): Эта часть сети принимает скрытое представление и пытается восстановить исходные данные. Декодер также состоит из нескольких слоев нейронной сети, которые постепенно увеличивают размерность данных обратно к размеру входных данных.
Применение автокодировщиков
Уменьшение размерности: Автокодировщики могут использоваться для уменьшения размерности данных, сохраняя при этом как можно больше информации. Это полезно для визуализации данных и предварительной обработки перед использованием других алгоритмов машинного обучения.
Обнаружение аномалий: Автокодировщики могут быть обучены на "нормальных" данных, а затем использоваться для обнаружения аномалий. Если модель не может хорошо реконструировать новые данные, это может указывать на аномалию.
Обучение признаков: Автокодировщики могут извлекать полезные признаки из данных, которые затем могут быть использованы в других задачах машинного обучения.
Генерация данных: Вариационные автокодировщики (VAE) могут генерировать новые данные, похожие на те, на которых они были обучены. Это полезно для задач, связанных с генеративным моделированием, таких как создание изображений, музыки или текста.
- Трансформеры (Transformers)
- Изначально разработаны для задач обработки естественного языка.
- Основаны на механизме внимания (attention mechanism).
- Примеры: BERT, GPT, T5.
- Графовые нейронные сети (Graph Neural Networks, GNN)
- Предназначены для работы с графовыми структурами данных.
- Примеры: Graph Convolutional Networks (GCN), Graph Attention Networks (GAT).
Эти типы нейросетей различаются архитектурными особенностями и методами обучения, что позволяет им решать широкий спектр задач, начиная от классификации изображений и заканчивая генерацией текста и моделированием сложных взаимодействий в графах.
Глубокое обучение (Deep Learning) и обычное машинное обучение (Traditional Machine Learning) отличаются по ряду характеристик и применяемых методов. Вот основные различия:
Основные различия
Архитектура моделей:
- Обычное машинное обучение: Используются модели с одним или несколькими "примитивными" слоями, например, линейная регрессия, логистическая регрессия, дерево решений, случайные леса, SVM и т.д.
- Глубокое обучение: Используются многослойные нейронные сети (глубокие сети) с большим числом слоев, такие как сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), автоэнкодеры, GAN и трансформеры.
Обработка данных:
- Обычное машинное обучение: Требует значительной предварительной обработки данных и извлечения признаков (feature engineering), часто вручную.
- Глубокое обучение: Автоматически извлекает признаки из данных благодаря архитектуре нейронной сети, особенно из сырых данных, таких как изображения, звук или текст.
Объем данных:
- Обычное машинное обучение: Эффективно работает с небольшими и средними объемами данных.
- Глубокое обучение: Требует больших объемов данных для эффективного обучения и достижения высоких результатов.
Обработка вычислений:
- Обычное машинное обучение: Требует меньше вычислительных ресурсов, может выполняться на обычных CPU.
- Глубокое обучение: Требует значительных вычислительных ресурсов, часто используются графические процессоры (GPU) или специализированное оборудование (TPU).
Обучение и настройка:
- Обычное машинное обучение: Процесс обучения проще, требует меньше времени и настроек.
- Глубокое обучение: Процесс обучения сложнее, требует значительного времени и тонкой настройки гиперпараметров.
Примеры использования
Обычное машинное обучение:
- Прогнозирование цен на недвижимость с использованием линейной регрессии.
- Классификация спама с помощью наивного Байеса.
- Анализ клиентской оттока с использованием логистической регрессии или дерева решений.
Глубокое обучение:
- Распознавание изображений с помощью сверточных нейронных сетей (CNN).
- Обработка естественного языка и перевод текста с использованием рекуррентных нейронных сетей (RNN) и трансформеров.
- Генерация изображений с помощью генеративных состязательных сетей (GAN).
Заключение
Глубокое обучение — это подмножество машинного обучения, отличающееся более сложными архитектурами моделей, способностью работать с большими объемами данных и автоматическим извлечением признаков. Оно требует больше вычислительных ресурсов и данных для обучения, но может достичь более высоких результатов в сложных задачах, таких как распознавание изображений и обработка естественного языка.
Практикум
Персептрон – это одна из первых моделей искусственного нейрона, разработанная в 1957 году Фрэнком Розенблаттом. Персептрон представляет собой упрощённую математическую модель биологического нейрона и используется для решения задач классификации.
Основные компоненты персептрона:
- Входы (Input): Персептрон получает несколько входных сигналов $ x_1, x_2, ..., x_n $, которые могут быть признаками или значениями входных данных.
- Весовые коэффициенты (Weights): Каждый вход умножается на весовой коэффициент $ w_1, w_2, ..., w_n $, который определяет важность данного входа.
- Сумматор (Summation): Все взвешенные входы суммируются.
- Функция активации (Activation function): Сумма взвешенных входов проходит через функцию активации, которая определяет выходной сигнал персептрона. В простейшем случае используется пороговая функция.
- Выход (Output): Выходной сигнал персептрона, который может быть либо 0, либо 1, в зависимости от результата функции активации.
Формула:
Для одного нейрона персептрона выход ( y ) определяется следующим образом:
$ y = f\left(\sum_{i=1}^{n} w_i x_i + b\right) $
где:
- $ x_i $ – входные данные,
- $ w_i $ – весовые коэффициенты,
- $ b $ – смещение (bias),
- $ f $ – функция активации (например, пороговая функция, сигмоида и т.д.).
Обучение персептрона:
Процесс обучения персептрона заключается в корректировке весов на основе ошибок, сделанных во время предсказаний. Это осуществляется с помощью алгоритма градиентного спуска. Основные шаги включают:
- Инициализация весов случайными значениями.
- Предсказание выходного значения для каждого обучающего примера.
- Обновление весов на основе ошибки предсказания.
Алгоритм обновления весов:
- Вычисляется ошибка: $ \text{Ошибка} = \text{Ожидаемое значение} - \text{Предсказанное значение} $
- Корректируются веса: $ w_i = w_i + \eta \cdot \text{Ошибка} \cdot x_i $ где $ \eta $ – скорость обучения (learning rate), которая определяет размер шага коррекции весов.
Персептрон способен решать задачи линейно разделимых классов, однако он не может справиться с задачами, которые не являются линейно разделимыми, например, с задачей XOR. Для решения таких задач используются более сложные модели нейронных сетей, такие как многослойные персептроны (MLP) или другие архитектуры глубокого обучения.
python
import numpy as np
class Perceptron:
def __init__(self, learning_rate=0.01, n_iters=1000):
self.lr = learning_rate
self.n_iters = n_iters
self.activation_func = self._unit_step_func
self.weights = None
self.bias = None
def fit(self, X, y):
n_samples, n_features = X.shape
# Инициализация весов и смещения
self.weights = np.zeros(n_features)
self.bias = 0
y_ = np.array([1 if i > 0 else 0 for i in y])
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
linear_output = np.dot(x_i, self.weights) + self.bias
y_predicted = self.activation_func(linear_output)
# Обновление правил
update = self.lr * (y_[idx] - y_predicted)
self.weights += update * x_i
self.bias += update
def predict(self, X):
linear_output = np.dot(X, self.weights) + self.bias
y_predicted = self.activation_func(linear_output)
return y_predicted
def _unit_step_func(self, x):
return np.where(x >= 0, 1, 0)
# Пример использования:
if __name__ == "__main__":
# Набор данных (логическая функция "И")
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 0, 0, 1])
# Создание и обучение перцептрона
p = Perceptron(learning_rate=0.1, n_iters=10)
p.fit(X, y)
# Прогнозирование
predictions = p.predict(X)
print(f"Предсказания: {predictions}") Предсказания: [0 0 0 1]Feedforward neural network (FFNN) — это простой тип искусственной нейронной сети, в котором информация передается строго в одном направлении: от входных узлов через скрытые слои (если они есть) к выходному слою. Каждый узел в одном слое соединен с каждым узлом в следующем слое.
Пример простой FFNN на Python с использованием библиотеки PyTorch:
python
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# Определение класса Feedforward Neural Network
class FFNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(FFNN, self).__init__()
self.hidden = nn.Linear(input_size, hidden_size) # скрытый слой
self.output = nn.Linear(hidden_size, output_size) # выходной слой
def forward(self, x):
x = F.relu(self.hidden(x)) # Применяем функцию активации (ReLU) к скрытому слою
x = self.output(x) # Применяем выходной слой
return x
# Пример использования FFNN
if __name__ == '__main__':
# Задаем параметры сети
input_size = 10
hidden_size = 5
output_size = 2
# Создаем экземпляр сети
model = FFNN(input_size, hidden_size, output_size)
# Пример входных данных
input_data = torch.randn(3, input_size) # 3 примера размерности input_size
# Получаем предсказания модели
output = model(input_data)
print("Input data:")
print(input_data)
print("\nOutput predictions:")
print(output)Input data:
tensor([[-0.9476, -0.0782, -0.4216, 1.1078, -0.1836, -0.9386, 0.0983, 0.2548,
-1.5022, -0.1589],
[-0.0615, 0.4714, 1.8285, -0.6539, 0.1940, 0.5791, 0.1182, -0.1079,
0.3049, -0.6833],
[ 0.8615, -2.6671, -0.0652, -0.9974, -0.8473, -1.5384, -0.5453, -0.0518,
0.6404, 0.9048]])
Output predictions:
tensor([[ 0.5756, -0.1782],
[ 0.2046, -0.3160],
[ 0.0749, -0.4667]], grad_fn=<AddmmBackward0>)В этом примере:
FFNNопределяет класс модели нейронной сети с одним скрытым слоем и одним выходным слоем.torch.nn.Linearиспользуется для определения линейных (полносвязных) слоев сети.- Функция активации ReLU (
F.relu) применяется к выходу скрытого слоя. - Входные данные
input_dataпредставляют собой тензор размерности (3, input_size), где 3 - количество примеров. outputсодержит предсказания модели для входных данных.
Этот пример демонстрирует базовую структуру и работу простой feedforward нейронной сети на PyTorch.