Appearance
Домашнее задание: Обучение с учителем и без учителя. Д.З
Обучение с учителем (supervised learning) и без учителя (unsupervised learning) — две основные парадигмы машинного обучения, которые используются для решения различных задач.
Обучение с учителем (Supervised Learning)
Обучение с учителем включает в себя обучение модели на размеченных данных. Размеченные данные означают, что для каждого примера в наборе данных известен правильный ответ или метка.
Примеры задач обучения с учителем:
- Классификация: Предсказание категории или класса, к которому принадлежит объект.
- Пример: Распознавание изображений (определить, что изображено на картинке: кошка или собака).
- Регрессия: Предсказание непрерывного значения.
- Пример: Прогнозирование цен на недвижимость.
Основные этапы обучения с учителем:
- Сбор и разметка данных: Подготовка набора данных, где каждый пример имеет метку.
- Разделение данных: Деление набора данных на обучающую и тестовую части.
- Выбор модели: Определение алгоритма, который будет использоваться для обучения (например, линейная регрессия, дерево решений).
- Обучение модели: Использование обучающего набора данных для настройки параметров модели.
- Оценка модели: Проверка качества модели на тестовом наборе данных.
Обучение без учителя (Unsupervised Learning)
Обучение без учителя включает в себя обучение модели на неразмеченных данных. Модель должна самостоятельно выявить структуру или паттерны в данных.
Примеры задач обучения без учителя:
- Кластеризация: Группировка объектов в кластеры на основе их сходства.
- Пример: Сегментация клиентов по схожести их покупательских привычек.
- Поиск ассоциаций: Выявление правил ассоциаций между объектами в данных.
- Пример: Анализ рыночной корзины (какие продукты часто покупаются вместе).
Основные этапы обучения без учителя:
- Сбор данных: Подготовка набора данных без меток.
- Выбор алгоритма: Определение алгоритма, который будет использоваться для обучения (например, k-means, алгоритм ассоциации).
- Обучение модели: Применение алгоритма к данным для выявления структур или паттернов.
- Интерпретация результатов: Анализ полученных результатов и их интерпретация.
Домашнее задание
Создайте копию блокнота. Далее выполнйте задания в ней.
Теоретическая часть:
- Опишите различия между обучением с учителем и без учителя.
- Приведите примеры задач, которые решаются с помощью обучения с учителем, и задачи, которые решаются с помощью обучения без учителя.
Практическая часть:
- Найдите датасет, который можно использовать для обучения с учителем и без учителя. (Например, датасет "Wine" из библиотеки Scikit-Learn. Этот датасет содержит информацию о химическом составе различных вин и их классах (три разных сорта вина)).
- Реализуйте алгоритм обучения с учителем и без учителя. Интерпретируйте результаты.
python
# Импортируем необходимые библиотеки
import numpy as np
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_reportСсылку на ваш блокнот разместите в домашнем задании.
Удачи в выполнении задания! Если возникнут вопросы, не стесняйтесь обращаться за помощью.
Обучение с учителем: Классификация с использованием логистической регрессии
Используем датасет "Iris" для классификации видов ирисов.
python
# Импортируем необходимые библиотеки
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Загружаем датасет Iris
iris = load_iris()
X = iris.data
y = iris.target
# Разделяем данные на обучающую и тестовую части
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Обучаем модель логистической регрессии
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# Предсказываем результаты на тестовых данных
y_pred = model.predict(X_test)
# Оцениваем качество модели
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred)) Accuracy: 1.0
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 1.00 1.00 1.00 13
2 1.00 1.00 1.00 13
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45Пояснение к метрикам
Accuracy:
accuracy: Доля правильно предсказанных классов среди всех предсказаний. В данном случае, accuracy равна 1.00 (или 100%), что означает, что модель правильно предсказала все 45 примеров.
Macro Avg:
macro avg: Среднее арифметическое значения precision, recall и F1-score по всем классам. В данном случае все значения равны 1.00, что указывает на идеальную модель для всех классов. precision: Доля правильно предсказанных положительных результатов среди всех предсказанных положительных результатов. recall: Доля правильно предсказанных положительных результатов среди всех фактических положительных результатов. f1-score: Среднее гармоническое значение precision и recall, что позволяет учесть оба этих параметра.
Weighted Avg:
weighted avg: Взвешенное среднее значение precision, recall и F1-score по всем классам, где вес каждого класса пропорционален количеству истинных примеров этого класса. В данном случае все значения равны 1.00, что также указывает на идеальную модель. Взвешенное среднее полезно, когда классы неравномерно распределены, так как оно учитывает количество примеров каждого класса.
Обучение без учителя: Кластеризация с использованием алгоритма K-means
Используем тот же датасет "Iris" для кластеризации.
python
# Импортируем необходимые библиотеки
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Обучаем модель K-means
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# Предсказываем кластеры
clusters = kmeans.predict(X)
# Визуализируем результаты кластеризации
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis', marker='o')
plt.title('K-means Clustering of Iris Dataset')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.show()/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
<Figure size 640x480 with 1 Axes>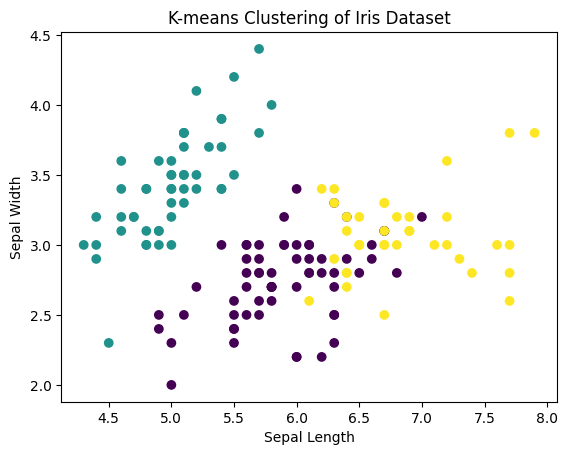
Пояснение коду
Обучение с учителем (Supervised Learning):
- Загружаем датасет Iris.
- Разделяем данные на обучающую и тестовую выборки.
- Обучаем модель логистической регрессии на обучающей выборке.
- Оцениваем модель на тестовой выборке, выводим точность и отчёт классификации.
Обучение без учителя (Unsupervised Learning):
- Загружаем датасет Iris.
- Обучаем модель K-means для кластеризации данных.
- Визуализируем результаты кластеризации, отображая кластеры на графике.