Appearance
Обучение с учителем и без учителя
Обучение с учителем (Supervised Learning)
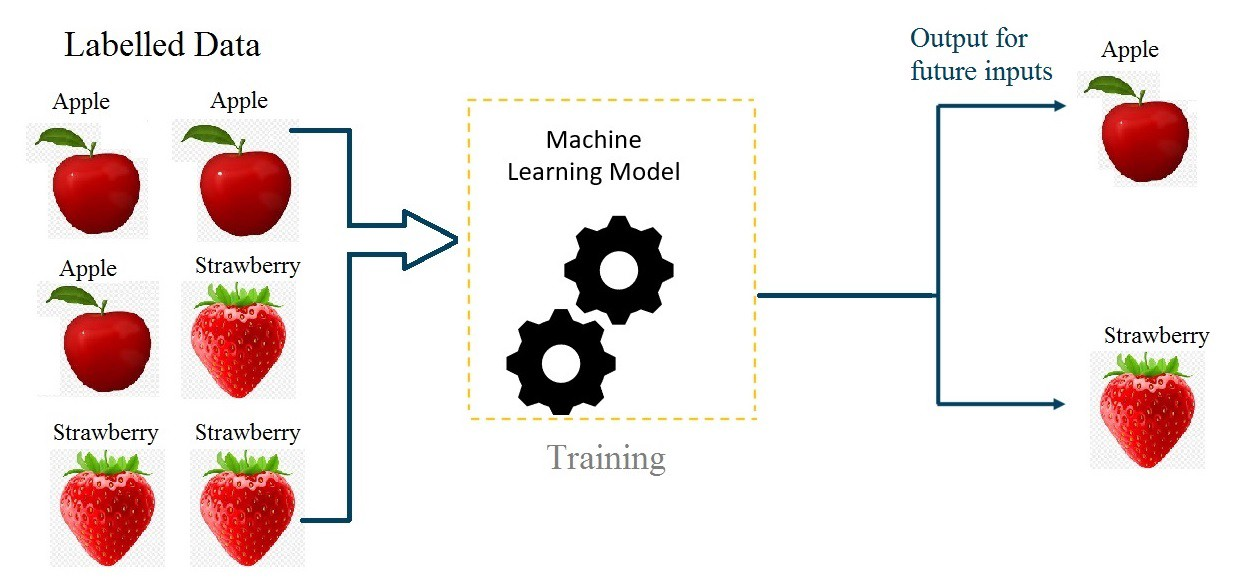
Описание
Обучение с учителем — это метод машинного обучения, при котором модель обучается на размеченных данных, то есть на данных, где каждый входной пример сопровождается правильным выходным значением или меткой. Цель обучения с учителем заключается в том, чтобы модель научилась предсказывать выходные значения для новых, невиданных данных на основе полученных знаний.
Примеры алгоритмов
- Линейная регрессия: Предсказывает непрерывное значение на основе входных данных.
python
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# Пример данных
X = np.array([[1, 1], [2, 3], [3, 3], [4, 5], [5, 5]])
y = np.array([1, 2, 2, 4, 5])
# Создание и обучение модели
model = LinearRegression()
model.fit(X, y)
# Предсказание для всех данных
y_pred = model.predict(X)
print("Mean Squared Error:", mean_squared_error(y, y_pred))
# Графическая визуализация фактических и предсказанных значений
plt.figure(figsize=(10, 6))
# Все фактические значения с увеличенным размером точек
plt.scatter(X[:, 0], y, color='blue', s=100, label='Actual values')
# Линия предсказанных значений
plt.plot(X[:, 0], y_pred, color='red', label='Predicted values', linestyle='dashed', marker='o')
plt.xlabel('X values')
plt.ylabel('y values')
plt.title('Actual vs Predicted values')
plt.legend()
plt.show()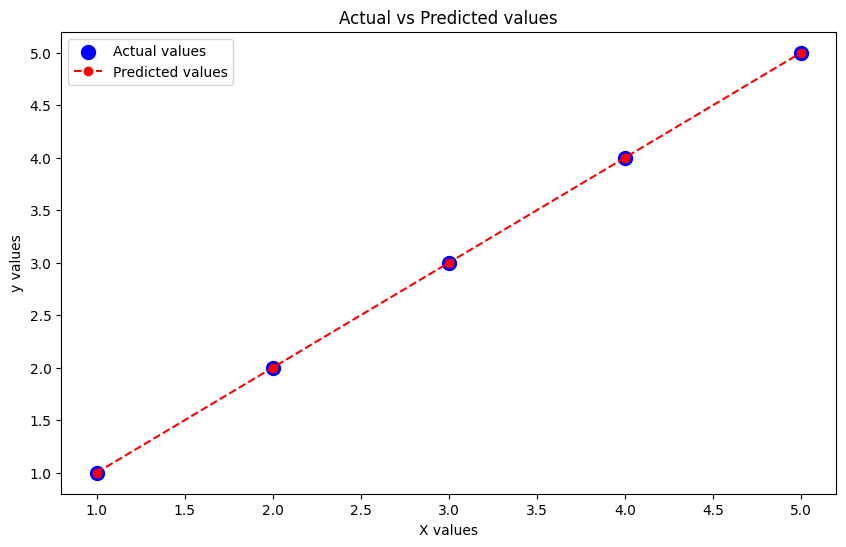
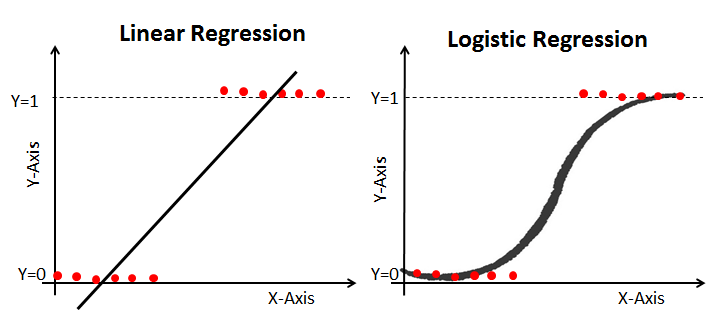
- Логистическая регрессия: Предсказывает вероятность принадлежности к классу, используется для бинарной классификации.
python
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Загрузка данных
iris = load_iris()
X = iris.data
y = (iris.target == 0).astype(int) # Целевой класс: 1 - Setosa, 0 - не Setosa
# Разделение данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создание и обучение модели логистической регрессии
model = LogisticRegression()
model.fit(X_train, y_train)
# Предсказание на тестовых данных
y_pred = model.predict(X_test)
# Оценка точности модели
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Вывод фактических и предсказанных классов
print(f'Actual classes: {y_test}')
print(f'Predicted classes: {y_pred}') Accuracy: 1.00
Actual classes: [0 1 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 1]
Predicted classes: [0 1 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 1]"Setosa" — это один из видов ирисов в знаменитом наборе данных "Iris", который используется для демонстрации и тестирования алгоритмов машинного обучения. Набор данных состоит из трех видов ирисов:
- Iris-setosa
- Iris-versicolor
- Iris-virginica
Каждый вид представлен 50 экземплярами, а каждый экземпляр описывается четырьмя признаками:
- Длина чашелистика (sepal length)
- Ширина чашелистика (sepal width)
- Длина лепестка (petal length)
- Ширина лепестка (petal width)
Цель нашего примера с логистической регрессией — классифицировать, является ли данный цветок ирисом вида "Setosa" или нет (бинарная классификация). В этом случае целевая переменная (метка) равна 1, если это Iris-setosa, и 0, если это Iris-versicolor или Iris-virginica.
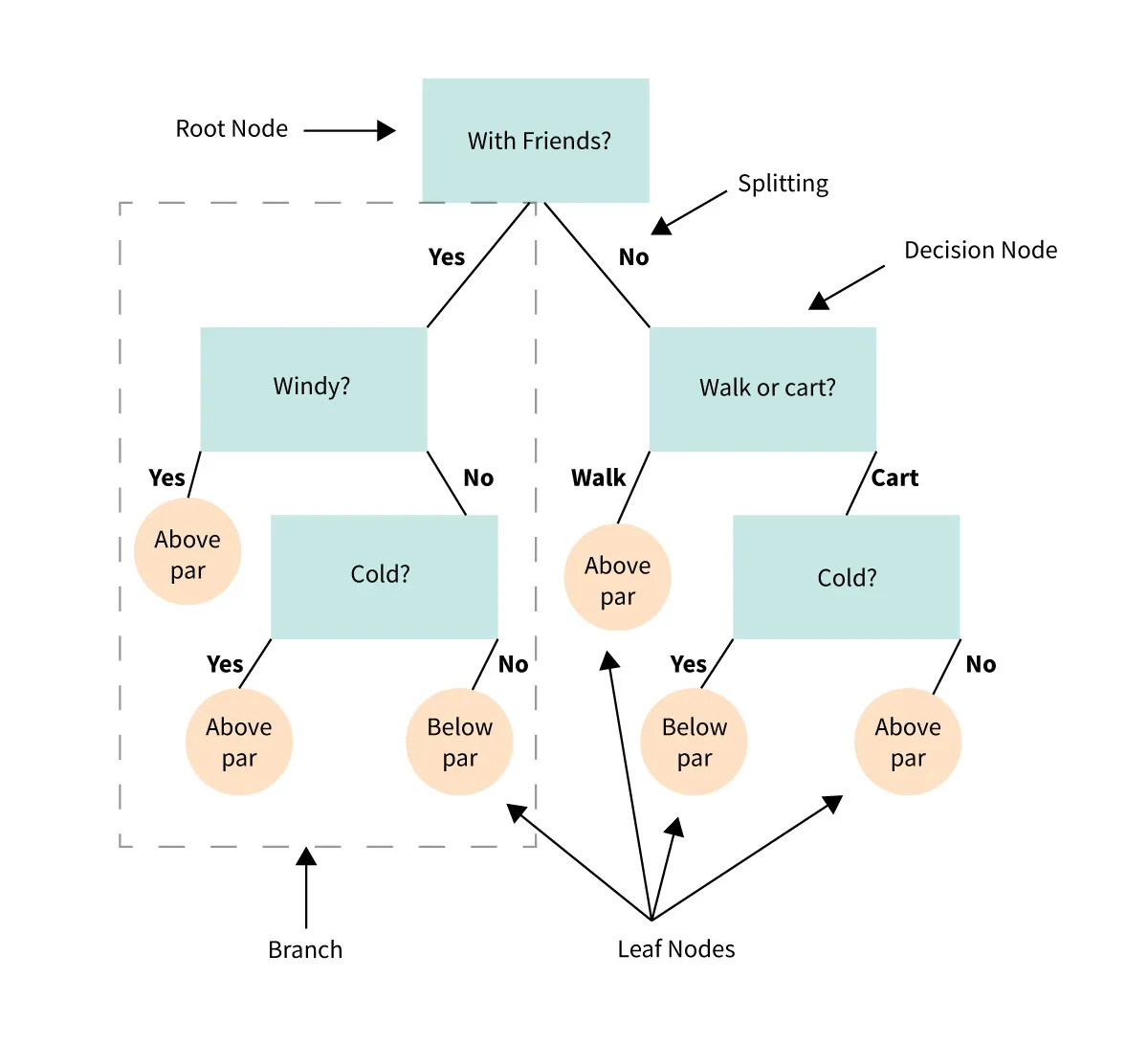
- Деревья решений: Делят пространство признаков на области, предсказывая метку для каждой области.
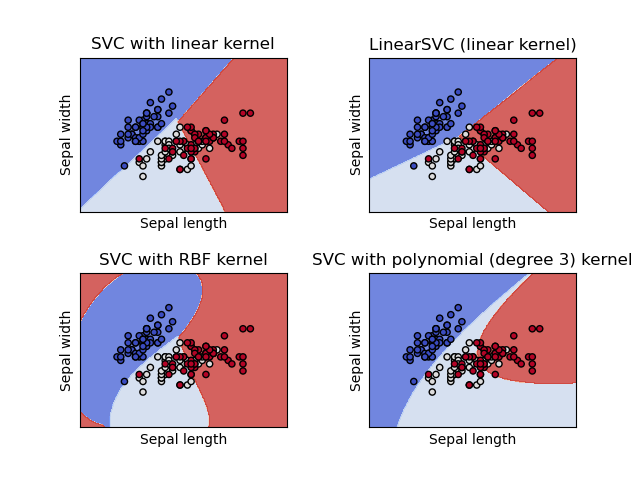
- Метод Опорных Векторов (SVM): Находят гиперплоскость, которая лучше всего разделяет классы.

- Нейронные сети: Обучаются на размеченных данных для сложных задач, таких как классификация изображений и распознавание речи.
Примеры применения
- Предсказание цен на недвижимость (линейная регрессия).
- Классификация писем как "спам" или "не спам" (логистическая регрессия).
- Распознавание изображений (нейронные сети).
- Диагностика заболеваний на основе медицинских данных (деревья решений, нейронные сети).
Обучение без учителя (Unsupervised Learning)
Описание
Обучение без учителя — это метод машинного обучения, при котором модель обучается на неразмеченных данных. В этом случае модель пытается выявить скрытые структуры или шаблоны в данных без предоставления правильных выходных значений.
Примеры алгоритмов
Кластеризация (Clustering):
- K-средних (K-means): Разделяет данные на ( K ) кластеров, минимизируя внутрикластерное расстояние.
- Иерархическая кластеризация (Hierarchical Clustering): Строит дерево кластеров на основе расстояний между примерами.
Снижение размерности (Dimensionality Reduction):
- PCA (Principal Component Analysis): Преобразует данные в новое пространство с уменьшенной размерностью, сохраняя как можно больше информации.
- t-SNE (t-Distributed Stochastic Neighbor Embedding): Визуализация высокоразмерных данных в низкоразмерном пространстве.
Ассоциативные правила (Association Rules):
- Алгоритм Apriori: Выявляет частые наборы предметов и ассоциативные правила в транзакционных базах данных.
Примеры применения
- Сегментация клиентов для маркетинга (кластеризация).
- Выявление аномалий в данных (кластеризация).
- Визуализация высокоразмерных данных (PCA, t-SNE).
- Рекомендательные системы (ассоциативные правила).
python
import numpy as np
from sklearn.cluster import KMeans
# Пример данных
X = np.array([[1, 2], [1.5, 1.8], [1, 0.6], [4, 2], [5, 3], [3.5, 2.2]])
# Создание и обучение модели KMeans с явным указанием n_init
kmeans = KMeans(n_clusters=2, n_init=10, random_state=42)
kmeans.fit(X)
# Получение центров кластеров и меток
cluster_centers = kmeans.cluster_centers_
labels = kmeans.labels_
print("Cluster centers:", cluster_centers)
print("Labels:", labels)
# Отображение точек данных с цветом в зависимости от меток кластеров
colors = ['blue', 'green']
for i in range(len(X)):
plt.scatter(X[i][0], X[i][1], color=colors[labels[i]], s=100)
# Отображение центров кластеров
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], color='red', marker='X', s=200, label='Cluster Centers')
plt.xlabel('X values')
plt.ylabel('Y values')
plt.title('KMeans Clustering')
plt.legend()
plt.show() Cluster centers: [[4.16666667 2.4 ]
[1.16666667 1.46666667]]
Labels: [1 1 1 0 0 0]
text/plain
<Figure size 640x480 with 1 Axes>
Сравнение и выбор подхода
Обучение с учителем:
- Используется, когда есть размеченные данные или данные можно разметить с приемлемыми трудозатратами.
- Применяется для задач классификации и регрессии.
- Требует наличия большого количества размеченных данных для обучения.
Обучение без учителя:
- Используется, когда размеченные данные отсутствуют.
- Применяется для задач кластеризации, выявления аномалий и снижения размерности.
- Полезно для выявления скрытых структур и шаблонов в данных.