Appearance
Aiogram 3: Магия фильтров
https://habr.com/ru/articles/821085/
Фильтры в aiogram нужны для того, чтобы бот понимал, как реагировать на то или иное событие (действие, сообщение или тип сообщения).
Фильтры по типу сообщения
На более высоком уровне мы указываем фильтры в декораторе перед функцией после роутера или диспетчера. Из наиболее часто используемых:
.messageСрабатывает на сообщения в личном чате с ботом или в группах (в каналах работать не будет). Здесь обрабатываются текстовые, фото, видео сообщения и сообщения с документами..callback_queryСрабатывает на сообщения, содержащиеcallbackдату..channel_postСрабатывает на сообщения в канале, который администрирует бот.
Магические фильтры
Магические фильтры, это самое глобальное и самое крутое обновление которое предложила своим пользователям библиотека aiogram 3 за долгое время. Грамотное использование этого нововведения позволяет разработчикам сокращать код, на фоне двойки, в полтора-два раза и это без преувеличений!
В прошлых статьях мы уже касались магических фильтров в таких реализациях:
F.text == "ПРИВЕТ"(тем самым говорили реагировать на сообщение “ПРИВЕТ”)F.data == "back_home"(тут говорили боту реагировать наCallData, которая равна"back_home")F.data.startswith("qst_")(тут говорили боту реагировать наCallData, которая начинается с"qst_").
Сами магические фильтры способны намного на большее и далее, на практических примерах, рассмотрим все возможности магических фильтров.
Магические фильтры отвечающие по типу контента.
Вот как записывается фильтры на тип сообщения:
F.text– обычное текстовое сообщение (уже такое делали)F.photo– сообщение с фотоF.video– сообщение с видеоF.animation– сообщение с анимацией (гифки)F.contact– сообщение с отправкой контактных данных (очень полезно для FSM)F.document– сообщение с файлом (тут может быть и фото, если оно отправлено документом)F.data– сообщение сCallData.
Достаточно указать, например, F.video, чтоб бот понимал что сейчас ему нужно будет произвести какое-то действие с видео.
Важно отметить. Если ничего не указывали в качестве аргументов декоратора хендлеров, бот воспринимал этот хендлер, по умолчанию как тип контента ANY, так что будьте осторожны.
С каждым типом сообщений можно прямо в декораторе прокручивать всякие трюки. Давайте рассмотрим трюки проверки текста на примере F.text.
python
F.text.len() == 5 # Длина текста равна 5.
F.text == 'Привет' # Текст сообщения равен 'Привет'
F.text != 'Пока!' # Текст сообщения не равен 'Пока!'
F.text.contains('Привет') # Текст сообщения содержит слово 'Привет'
F.text.lower().contains('привет') # Текст сообщения в малом регистре содержит слово 'привет'.
F.text.startswith('Привет') # Текст сообщения начинается со слова 'Привет'
F.text.endswith('дружище') # Текст сообщения заканчивается словом 'дружище'Это означает инвертирование результата операции с помощью побитового отрицания ~.
~F.text означает, что фильтр F.text будет инвертирован, что приведет к тому, что он будет противоположен исходному результату. Например, если F.text возвращает True (истина), то ~F.text вернет False (ложь), и наоборот.
~F.text.startswith('spam') означает, что результат операции F.text.startswith('spam') будет инвертирован. Это означает, что если сообщение начинается с spam, то результат будет True, и инвертированный результат, возвращенный ~, будет False, что означает, что сообщение не начинается с spam. Если результат операции F.text.startswith('spam') равен False (ложь), то инвертированный результат будет True, что означает, что сообщение начинается с spam.
Текст равен одному из вариантов сообщений. Предварительно само сообщение перегоняем в верхний регистр. Можно для проверки использовать, как множества (это надежнее) или список.
python
F.text.upper().in_({'ПРИВЕТ', 'ПОКА'})
F.text.upper().in_(['ПРИВЕТ', 'ПОКА'])Вот ещё несколько примеров этого же фильтра.
python
F.chat.type.in_({"group", "supergroup"})
f.content_type.in_({'text', 'sticker', 'photo'})Давайте напишем простой хендлер, который будет реагировать на слово «подписывайся» в сообщении (на других примерах мы усилим этот хендлер).
python
@start_router.message(F.text.lower().contains('подписывайся'))
async def process_find_word(message: Message):
await message.answer('В твоем сообщении было найдено слово "подписывайся", а у нас такое писать запрещено!')Я установил малый регистр текста, а внутри уже провел проверку на содержание в тексте слова 'подписывайся', если запись выглядела бы так F.text.lower().contains('Подписывайся'), то условие никогда бы не было выполнено, ведь мы предварительно текст привели в малый регистр.
Такая запись позволила нам игнорировать регистр. Проверяем:
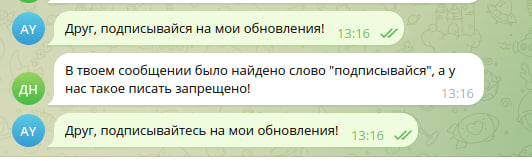
Все работает.
Есть возможность обработки регулярных выражений в этих фильтрах.
Давайте рассмотрим случай, когда мы хотим проверить, начинается ли сообщение с русского слова "Привет" (с учетом различных регистров) и затем содержит любой текст. Вот как это можно сделать:
python
F.text.regexp(r'(?i)^Привет, .+')В этой регулярке:
(?i)включает игнорирование регистра, то есть регулярное выражение будет искать "Привет" независимо от того, написано оно с заглавной или строчной буквы.^обозначает начало строки.Привет,, ищет словоПривети запятую после него..+обозначает один или более любых символов после слова "Привет,".
А вот пример такого кода:
python
@start_router.message(F.text.regexp(r'(?i)^Привет, .+'))
async def process_find_reg(message: Message):
await message.answer('И тебе здарова! Че нада?')Тестируем:
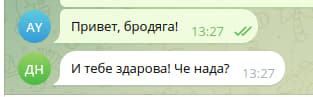
Все работает, если можно не использовать регулярки — не используйте, т.к. регулярные выражения плохо читаемы и увеличивают вероятность ошибки.
А теперь давайте научимся использовать сразу несколько магических фильтров в одном хендлере. В этом нам помогут 2 оператора: & - аналог and и | - аналог or. Кроме того каждое условие нужно брать в скобки.
Тут мы сделали проверку, что айди пользователя равен 1245555 и что он ввел текст 'Хочу в админку!'.
python(F.from_user.id == 1245555) & (F.text == 'Хочу в админку!')Проверка на то, что сообщение начинается на «Привет» или заканчивается на «Пока».
pythonF.text.startswith('Привет') | F.text.endswith('Пока')А это уже более сложный пример. Тут сделали проверку на то находится ли id пользователя во множестве
сообщение начинается на
!или что сообщение начинается на/+ текст содержит словоban.python(F.from_user.id.in_({42, 777, 911})) & (F.text.startswith('!') | F.text.startswith('/')) & F.text.contains('ban')
Как вы видите — ограничение только в вашей фантазии, но если недостаточно магических фильтров. aiogram 3 дал возможность делать собственные фильтры.